

Logic Over Data

The information age has long been underway. The money-ball effect has infiltrated much of society; from sports to finances and beyond. And it’s no doubt that AI has already, and will continue to, impact our lives in more and more meaningful ways as we head into the future.
I’ve recently started dabbling into data science and machine learning. Partly because I find the field fascinating. Another, in an attempt to know thy enemy.
I would barely call myself a novice at this point (maybe even a mere tourist on the subject), but I feel like I can already start to form the outlines on which domains this AI push will have the greatest impacts.
ChatGPT (you may have heard of it) swept the nation in 2024. I use it all the time to help with my writing - I’ve found it to be a great way to narrow in on a word or phrase that’s on the tip of my tongue. It’s also great with cover letters, resumes, document summarization, and as the first step in the research process on a new subject. And, of course, it’s amazing for small coding projects.
But I’ve also found, especially when dealing in my domain(s) of expertise, that it can often times be blatantly wrong. Somehow this was monikered with the cute euphemism “hallucination”. You can eventually hone in on the correct answer with the right prompts, but you have to first know that it’s wrong before you can coax the correct answer out of it.
I’m not here to bash AI and LLMs. Doing that is like being the guy that didn’t “believe in computers” in the 1980’s.
That said, error is a big part of data science.
You’ll often see plots like this:
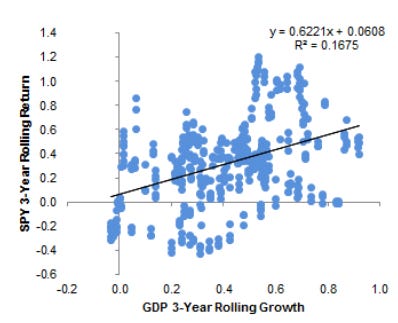
To the typical visual observer, this data probably looks like buckshot. To a statistician, there’s clear statistical significance.
There are certain domains where a wide range of error is okay. Renaissance Technologies changed the quant landscape by making massive sums of money by being correct on only 50.75% of their trades (just a whisker better than a coin flip).
Other domains, not so much. A self driving car needs to recognize a stop sign 100% of the time. Notably, machine vision models are already getting very close to this (though, not all self driving vehicles are created equally).
Domains where data and history are limited, especially combined with complex interactions between variables, are reason enough to be cautious.
This especially pertains to financial markets, where things are changing all the time. Accounting rules have evolved a great deal since the creation of the SEC. Coming off the Gold-Standard also bifurcates the data. As a general rule, I think we need to be aware that we can perform the same action in two different regimes and expect wildly different results. These actions could range anywhere from raising interest rates, implementing tariffs, and of course, the most recent hot topic - deficit spending.
ML can accommodate this to a degree, but a lot of these conditions have only occurred a couple of times in modern history. You can’t have a ton of confidence when N=2.
And what about extrapolation?
As Morgan Housel puts it, “Things that have never happened before happen all the time.” Which is also a great reminder of Nassim Taleb’s “turkey problem”:
Consider a turkey that is fed every day, every single feeding will firm up the bird’s belief that it is the general rule of life to be fed every day by friendly members of the human race…On the afternoon of the Wednesday before Thanksgiving, something unexpected will happen to the turkey. It will incur a revision of belief.
~ Nassim Taleb, Black Swan
AI does amazingly well with interpolation - or predicting an output for inputs inside the boundary of a well defined historical data set. Those predictions get less useful the further outside that boundary you get, and completely useless when something that’s never happened before, happens.
Big Data Required
Another thing that I see often is making sweeping assumptions based on small data sets. You’ll often hear about the yield curve inversion’s track record in predicting recessions. Or more recently, the Sahm rule - which was broken practically the moment it hit the mainstream.
Causation & Correlation
In regards to yield curve inversions and the Sahm rule, the problem is these aren’t laws of the universe. There’s nothing innate that binds the independent variable to the dependent one.
I’ve struggled for so long trying to come up with a good reason for why an inverted yield curve “must” be a predictor of recession. I certainly understand that an inversion isn’t a “natural” state. But there may be several explanations for why an inversion might be benign. One being what we’ve recently witnessed coming out of Covid era supply shocks. If short duration interest rates need to be raised to fight short-term inflation while long run inflation expectations remain low, then it makes sense that short duration bond yields could rise above longer duration ones (i.e., an inverted yield curve).
The ability to explain the relationship between data & outcome is more important than the relationship, itself. This is something AI may lag behind for quite some time…Logic Over Data.
Closed Systems vs Chaotic Systems
The fact that computers have mastered games like chess is nothing short of incredible. There are more potential chess games than there are atoms in the known universe. And mastering Go is even more impressive.
But, these are systems with very defined rules and boundaries.
I would say self driving cars also falls into this bucket. At the end of the day, the rules of the road are pretty basic: stay in your lane, adhere to traffic signals, and don’t hit anyone. I would surmise that the computer vision aspect is orders of magnitude more difficult to reign in than the actual driving part.
For chaotic systems, on the other hand, artificial intelligence will have a more difficult path to mastering. As mentioned previously, financial markets, at a macro level, might fall into this bucket. A model in this domain may behave well when conditions are typical. But if variables extend well outside the bounds of the historical data set or interactions between variables haven’t been properly captured by the model, it’s actions could fare far worse than a skilled practitioner that relies on judgement.
How Can We Stand Apart
Depth over breadth. As mentioned earlier, I’ve already noticed that LLM’s perform quite poorly when asked very in-depth questions about fields that I’m intimately familiar with. This knowledge gap will probably close over time, but this seems like a reasonable strategy for the foreseeable future.
Don’t forget breadth. In the same vein, humans are incredible at making analogies across domains. Knowing a little bit about many topics and having the ability to marry ideas between them to form new ideas is a super power.
Avoid professions where your primary function is simply summarizing data and/or providing surface level interpretation. This is where AI will continue to thrive.
Avoid professions where the primary function is performing repetitive tasks, even if complex.
Pursue evolving fields. You can effectively outrun AI in these domains.
One of One. Any topic or problem where the sample size is very small will be less ‘solvable’ by conventional ML solutions. Become the person that tackles unique problems.
Be willing to view the world in a way that veers from consensus…obviously, don’t be contrarian for its own sake — 1+1 will always equal 2. But having an intimate understanding of a topic area offers the ability to frame problems in ways that offer better insight.
In a world where machines are getting better at doing the average, our edge will continue to lie in the non-average.